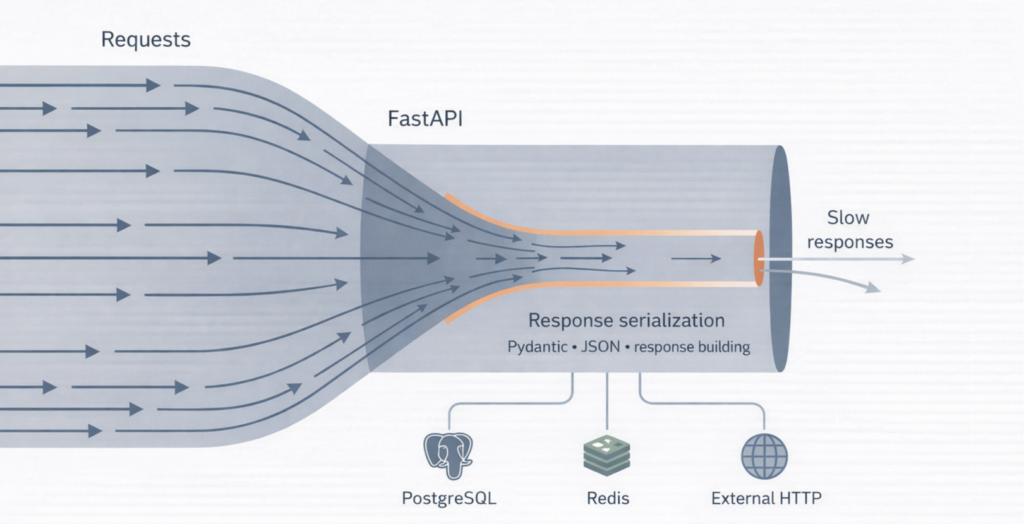
FastAPI выбирают за скорость, удобство и асинхронность. Но на одном из наших проектов API при нагрузке всего 150 RPS начал отвечать по 3–5 секунд, а иногда и вовсе падал по таймаутам.
При этом по инфраструктуре всё выглядело вполне нормально:
- CPU держался в районе 35–40%
- PostgreSQL не показывал долгих запросов
- сеть тоже не выглядела узким местом
На первый взгляд — никаких явных проблем. Но пользователи ждали ответа секундами. Разберёмся, что произошло.
Архитектура сервиса
Стек был вполне типичный:
- FastAPI
- PostgreSQL
- SQLAlchemy 2.0 (async)
- Redis
- Docker + Kubernetes
- Uvicorn + Gunicorn
Один из эндпоинтов в упрощённом виде выглядел так:
@router.get("/orders/{order_id}")
async def get_order(order_id: int, db: AsyncSession = Depends(get_db)):
order = await order_service.get_order(order_id, db)
return orderВнутри обработчика происходило три вещи:
- запрос в PostgreSQL
- запрос в Redis
- HTTP-запрос во внешний сервис
И всё это — через async. Казалось бы, откуда тут вообще взяться задержкам.
Симптомы под нагрузкой
Картина деградации была очень характерной:
Когда latency растёт вот так, ступенчато, а база при этом «молчит», обычно стоит смотреть в две стороны:
- мы где-то упираемся в CPU, но не видим этого по общей загрузке
- или есть узкое место в event loop, из-за которого сервис начинает работать как очередь
Профилирование
Первым делом запустили py-spy:
py-spy top --pid <pid>Результат оказался неожиданным:
- около 40% времени уходило в
json.dumps - около 30% — в сериализацию Pydantic
- около 20% — в обработку результатов SQLAlchemy
То есть event loop тратил заметную часть времени не на базу и не на сеть, а на сборку и сериализацию ответа.
Проблема №1: дорогая сериализация через Pydantic
Эндпоинт возвращал довольно большой объект:
class OrderResponse(BaseModel):
id: int
items: list[Item]
customer: CustomerУ некоторых заказов было 200+ позиций. В результате на каждый запрос происходила такая цепочка:
Это удобно, безопасно и красиво. Но дорого — особенно если ответ большой, запросов много, а сериализация происходит на каждом запросе.
Проблема №2: классический N+1 в SQLAlchemy
Вторая проблема оказалась ещё более банальной.
order = await session.get(Order, order_id)
items = order.itemsСвязь items загружалась лениво. Если в заказе 200 позиций, это легко означает 200 дополнительных SQL-запросов.
На одном запросе такое поведение может быть не слишком заметно. Но под нагрузкой арифметика становится неприятной очень быстро.
Что происходило на каждом запросе
Фактически сервис делал примерно следующее:
- 1 запрос за Order
- до 200 запросов за Items
- создание сотен Pydantic-объектов
- сериализацию ответа в JSON
По отдельности каждая операция выглядела «нестрашно». Вместе — превращали сервис в очередь, и latency улетал в секунды.
Что сделали
1. Убрали N+1 через eager loading
Перевели загрузку связанных сущностей на selectinload:
stmt = (
select(Order)
.options(selectinload(Order.items))
.where(Order.id == order_id)
)
result = await session.execute(stmt)
order = result.scalar_one()После этого схема стала такой:
- 1 запрос за Order
- 1 запрос за Items
Уже одно это сильно разгрузило сервис.
2. Снизили накладные расходы Pydantic там, где это оправдано
Было:
return OrderResponse.model_validate(order)Стало:
return {
"id": order.id,
"items": [{"id": i.id, "price": i.price} for i in order.items],
}В нашем случае это почти вдвое уменьшило latency.
Важно: мы не отказались от Pydantic полностью. Мы оставили его там, где он действительно полезен — на границах системы, для валидации входящих данных и там, где важна строгая схема. Но перестали без необходимости прогонять через него большие вложенные объекты целиком.
3. Подключили более быстрый JSON-энкодер — orjson
Добавили ORJSONResponse:
from fastapi.responses import ORJSONResponse
app = FastAPI(default_response_class=ORJSONResponse)На больших ответах прирост оказался очень заметным: примерно в 3–5 раз быстрее на этапе сериализации. Конкретная цифра зависит от структуры данных, но в нашем случае эффект был далеко не косметическим.
4. Параллелизовали внешние запросы
До этого внешние HTTP-запросы выполнялись последовательно:
data1 = await client.get(url1)
data2 = await client.get(url2)
data3 = await client.get(url3)Переделали на параллельное выполнение:
data1, data2, data3 = await asyncio.gather(
client.get(url1),
client.get(url2),
client.get(url3),
)Если запросы независимы друг от друга, это даёт хороший выигрыш по времени ответа.
Итог после фиксов
После оптимизаций сервис стал держать в 3–4 раза больше нагрузки.
Выводы
- Async не значит «быстро». Асинхронность помогает пережидать I/O, но не спасает от тяжёлой сериализации и лишней работы на CPU.
- N+1 долго остаётся незаметным. Пока нагрузка маленькая, такой код может выглядеть вполне рабочим. Под нагрузкой он быстро превращается в серьёзное узкое место.
- Большие ответы — это дорогая операция. Чем больше объект ответа, тем выше цена сериализации, валидации и преобразований.
- Сначала профилирование, потом оптимизация. Иначе легко потратить время на улучшение не того участка системы.
Что проверить, если FastAPI внезапно стал медленным
- нет ли блокирующего кода:
requests, синхронных клиентов, тяжёлых операций в Python - нет ли N+1 в ORM
- сколько времени уходит на сериализацию Pydantic
- какой JSON-энкодер используется
- правильно ли подобраны workers, таймауты и лимиты сервера
Итог
Иногда проблема не в базе. Иногда не в сети. Иногда даже не во внешних сервисах.
Иногда всё упирается в то, как именно вы собираете и сериализуете ответ. И это — один из самых частых и неприятных продакшен-сюрпризов в Python-сервисах.